
Intro to supervised relation extraction
Relation Extraction(RE) is the method to finding and classifying semantic relations among entities mentioned in a text.
For example, suppose we have text:
Shaka khan born in Dhaka.
Here entities are Shaka Khan-> PERSON, Dhaka-> LOCATION.
and relation is: BIRTHPLACE.
So, how can we do this work in supervised classification?
So, let’s start………
Let’s say, our datasets is:
Sentence: Shaka khan born in Dhaka.
Tokens: ['Shaka', 'khan', 'born', 'in', 'Dhaka']
Entities: [B-PER, I-PER, O, O, B-LOC]
So, before feeding this data to classifier, we need to convert it to:
[PERSON] born in [LOCATION]
Then we feed this modified data to classifier and classifier will predict relation between entities, like BIRTHPLACE or NO-RELATION.
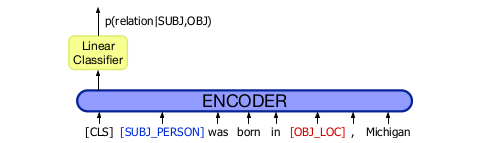
This image describe the whole process in briefly. For encoder, you can use any encoder like BERT, LSTM, GRU etc.
Comments