
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
Mertices
The following five evaluation metrics are available.
- ROUGE-N: Overlap of N-grams between the system and reference summaries.
- ROUGE-1 refers to the overlap of 1-gram (each word) between the system and reference summaries.
- ROUGE-2 refers to the overlap of bigrams between the system and reference summaries.
- ROUGE-L: Longest Common Subsequence (LCS) based statistics. Longest common subsequence problem takes into account sentence level structure similarity naturally and identifies longest co-occurring in sequence n-grams automatically.
- ROUGE-W: Weighted LCS-based statistics that favors consecutive LCSes .
- ROUGE-S: Skip-bigram[5] based co-occurrence statistics. Skip-bigram is any pair of words in their sentence order.
- ROUGE-SU: Skip-bigram plus unigram-based co-occurrence statistics.
Example:
System Summary:
the cat was found under the bed
Reference Summary :
the cat was under the bed
System Summary Bigrams:
the cat,
cat was,
was found,
found under,
under the,
the bed
Reference Summary Bigrams:
the cat,
cat was,
was under,
under the,
the bed
Based on the bigrams above, the ROUGE-2 recall is as follows:
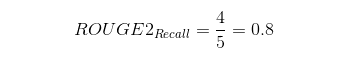
Essentially, the system summary has recovered 4 bigrams out of 5 bigrams from the reference summary which is pretty good! Now the ROUGE-2 precision is as follows:
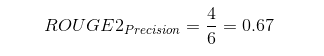
The precision here tells us that out of all the system summary bigrams, there is a 67% overlap with the reference summary.
Python code for calculating ROUGE value
Code was copied from this github repository. Clone that repository and run the following example from that directory
from PyRouge.pyrouge import Rouge
r = Rouge()
system_generated_summary = "The Kyrgyz President pushed through the law requiring the use of ink during the upcoming Parliamentary and Presidential elections In an effort to live up to its reputation in the 1990s as an island of democracy. The use of ink is one part of a general effort to show commitment towards more open elections. improper use of this type of ink can cause additional problems as the elections in Afghanistan showed. The use of ink and readers by itself is not a panacea for election ills."
manual_summmary = "The use of invisible ink and ultraviolet readers in the elections of the Kyrgyz Republic which is a small, mountainous state of the former Soviet republic, causing both worries and guarded optimism among different sectors of the population. Though the actual technology behind the ink is not complicated, the presence of ultraviolet light (of the kind used to verify money) causes the ink to glow with a neon yellow light. But, this use of the new technology has caused a lot of problems. "
[precision, recall, f_score] = r.rouge_l([system_generated_summary], [manual_summmary])
print("Precision is :"+str(precision)+"\nRecall is :"+str(recall)+"\nF Score is :"+str(f_score))
#output
"""
Precision is :0.446058091286
Recall is :0.439672801636
F Score is :0.442843380487
"""
- Installing PyRouge and use easily from this link.
Comments