
PALM: Pre-training an Autoencoding & Autoregressive Language Model for Context-conditioned Generation
PALM Paper: https://arxiv.org/pdf/2004.07159.pdf
PALM Code: https://github.com/overwindows/PALM

Before dive into the paper, let’s understand what is Autoencoding and Autoregressive pre-training.
Autoencoding
Autoencoding based pre-training aims to reconstruct the original text from corrupted input.
Like BERT[2] and it’s variant RoBERTa[3] and ALBERT[4], where a certain portion of input tokens are replaced by a special symbol [MASK]. The models are trained to recover the original tokens from the corrupted version by utilizing bidirectional context.
Autoregressive
An autoregressive model, such as GPT[6] is only trained to encode unidirectional context (either forward or backward).
Specifically, at each output timestep, a token is sampled from the models predicted distribution and the sample is fed back into the model to produce a prediction for the next output timestep, and so on. Which lacks an encoder to condition generation on context.
Problem with Autoencoding, Autoregressive and Encoder-Decoder
Autoencoding Problem: Autoencoding methods are not applicable to text generation where bidirectional contexts are not available.
Autoregressive Problem: While applicable to text generation, the autoregressive methods are not effective at modeling deep bidirectional context. On the contrary, downstream generation tasks often ask a model to condition generation on given textual context. This results in a gap between autoregressive modeling and effective pre-training.
Encoder-Decoder Problem: BART[5], MASS[7] both transformers based encoder decoder model with a bidirectional encoder and left-to-right decoder reconstruct the text.
These kind of generation is good for where generated text comes from input but with manipulated.
These are not good for comprehension-based generation.
PALM
To close the gap, PALM is carefully designed to autoregressively generate a text sequence by comprehending the given context in a bidirectional autoencoding manner.
In particular, PALM delegates autoencoding-based comprehension to the encoder in Transformer, and autoregressive generation to the Transformer[1] decoder.
So PALM is design for generating text from a given context. PALM, a novel approach to Pre-training an Autoencoding&autoregressive Language Model for text generation based on reading comprehension of textual context.
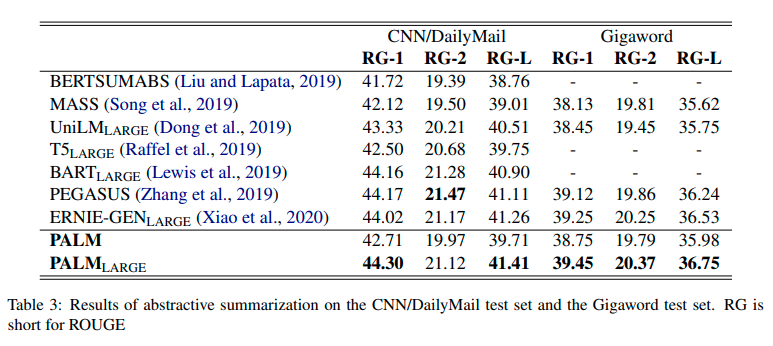
PALM significantly advances the state-of-the art results on a variety of language generation applications, including generative QA, abstractive summarization, question generation, and conversational response generation.
PALM Model
-
The
encoderis first trained as a bidirectional autoencoder to reconstruct the original text from corrupted context in which random tokens are sampled and replaced with [MASK] symbols following BERT’s practice (Devlin et al., 2018). The training optimizes the crossentropy reconstruction loss between encoder’s output and original context, as Masked Language Modeling (MLM) in BERT. By predicting the actual tokens in context that are masked out, PALM forces the encoder to comprehend the meaning of the unmasked tokens and the full context.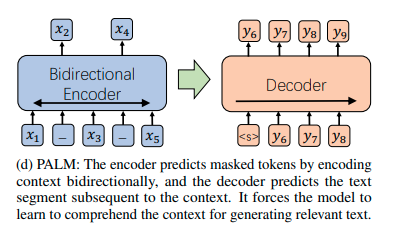
-
The encoder and decoder are then jointly trained to autoregressively generate text output out of the context representations from the encoder. The training maximizes the loglikelihood of the text in ground truth from the decoder’s output.

PALM also incorporate Pointer-Generator Networks(PGN)[8] on to top of the decoder to copy token from the context.
PALM Input Output Representation
Given a contiguous text fragment of length L (composed of a few sentences) from an unlabeled corpus, PALM uses the consecutive span of length 80% · L from the beginning of the fragment as context input to the encoder, and uses the remainder of text span of length 20% · L as text output to be generated by the decoder. This representation design mimics the input and output of downstream tasks, with the hypothesis that human-written text is coherent and thus the subsequent text span of length 20% · L captures the comprehension of the preceding context span. In this way, PALM learns to infer the subsequent text content from the preceding content. Maximum length of a fragment to be 500, i.e., L ≤ 500.
Experiments
Pre-training Datasets
- Wikipedia
- Book Corpus
Data was processed by wordpiece tokenizer
Pre-training Setup
PALM is based on the Transformer which consists of a 12-layer encoder and a 12-layer decoder with 768 embedding/hidden size, 3072 feed-forward filter size and 12 attention heads.
The parameters of PALM’s encoder are initialized by the pre-trained RoBERTa model which was trained with the Masked LM objective, removing Next Sentence Prediction from BERT.
Here is other hyper-parameter setup:
- dropout: 0.1
- learning rate: 1e-5 with linear warmup after 10k steps and linear decay
- batch size: minibatch containing 64 sequences of maximum length 500 tokens
-
machine: 16 NVIDIA V100 GPU cards for 800K steps
Comments